In this notebook, we will explore the basics of unsupervised learning, a type of machine learning that deals with unlabeled data. Unlike supervised learning, where the model is trained on labeled data, unsupervised learning algorithms try to find patterns and relationships in the data without any prior knowledge of the outcomes. We will cover here two different applications: clustering and dimensionality reduction.
1 Clustering
Clustering refers to the task of grouping data points into coherent categories without using labels. The goal is to assign samples to clusters such that points within the same group are similar to each other while being dissimilar to points in other groups. We will review here the most popular clustering algorithm, k-means, although many others exists, such as Gaussian Mixture Models (GMMs), DBSCAN, or hierarchical clustering.
1.1 k-means
k-means is an iterative clustering algorithm that partitions a dataset into \(k\) clusters by minimizing the total within-cluster variance. Given data points \(\{x_1, \dots, x_N\} \subset \mathbb{R}^d\), the objective is to find cluster assignments and centroids \(\{\mu_1, \dots, \mu_k\}\) that minimize
where \(c(i)\) denotes the index of the cluster assigned to point \(x_i\).
The algorithm alternates between two steps:
Assignment step: Assign each point to the nearest centroid, \[\begin{equation}
c(i) = \arg\min_{j = 1,\dots, k} \left\| x_i - \mu_j \right\|^2 .
\end{equation}\]
Update step: Recompute each centroid as the mean of its assigned points, \[\begin{equation}
\mu_j = \frac{1}{|\{i : c(i) = j\}|}
\sum_{i : c(i) = j} x_i .
\end{equation}\]
These steps are repeated until convergence, typically when assignments no longer change or the loss decreases negligibly.
k-means is computationally efficient and performs well when clusters are roughly spherical, similarly sized, and well separated. However, it is sensitive to initialization, cannot capture complex cluster shapes, and provides no probabilistic interpretation. It is therefore mainly used as a baseline clustering method or as preprocessing in more advanced unsupervised workflows.
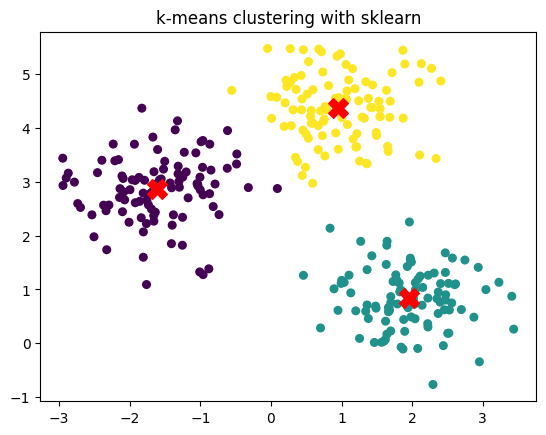
To implement it, we can use the KMeans class from the sklearn.cluster module. Here’s an example of how to use it:
from sklearn.cluster import KMeansfrom sklearn.datasets import make_blobsimport matplotlib.pyplot as plt# Generate synthetic 2D dataX, y_true = make_blobs(n_samples=300, centers=3, cluster_std=0.60, random_state=0)# Fit k-means with k = 3kmeans = KMeans(n_clusters=3, random_state=0)kmeans.fit(X)# Predicted cluster labelsy_pred = kmeans.labels_# Cluster centerscenters = kmeans.cluster_centers_# Plotplt.scatter(X[:, 0], X[:, 1], c=y_pred, s=30, cmap='viridis')plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, marker='X')plt.title("k-means clustering with sklearn")
Text(0.5, 1.0, 'k-means clustering with sklearn')
2 Dimensionality reduction
Dimensionality reduction aims to represent high-dimensional data in a lower-dimensional space while preserving as much of its relevant structure as possible. Many real-world datasets—images, trajectories, physical states—lie near a low-dimensional manifold embedded in a high-dimensional space, making it inefficient or unstable to work directly in the original representation. Reducing dimensionality allows us to compress data, visualize complex structures, remove noise, and simplify downstream tasks.
Classical methods such as PCA provide a linear projection that captures directions of maximal variance, giving a simple and interpretable baseline. However, many datasets exhibit nonlinear relationships that linear methods cannot capture. In such cases, neural network–based approaches like autoencoders offer a flexible framework for learning nonlinear low-dimensional embeddings through an encoder–decoder architecture.
This section introduces both perspectives: first, PCA as a principled linear method, and then autoencoders as a nonlinear generalization capable of learning richer, data-adapted latent spaces.
2.1 Principal Component Analysis (PCA)
You can find a more in depth introduction to PCA in this notebook from B. Requena, fro mwhich this section is inspired.
Principal Component Analysis (PCA) is a classical method for linear dimensionality reduction that seeks a low-dimensional representation of the data while preserving as much variance as possible. Given centered data points \(\{x_1, \dots, x_n\}\), with \(x \in \mathbb{R}^d\), PCA looks for an orthonormal set of directions, onto which the projection of the data maximizes total variance. To do so, we start by computing the data matrix \(X \in \mathbb{R}^{n \times d}\), where each row corresponds to a data point. We then compute the covariance as
\[\begin{equation}
C = \frac{1}{n} (X - \bar{X})^\top (X - \bar{X})
\end{equation}\] where \(\bar{X}\) is the mean of the dataset. In practice, we rather consider the centered data matrix \(X_c = X - \bar{X}\), where now every feature has mean zero. The covariance matrix is a \(d\times d\) symmetric matrix where every entry \(C_{ij}\) represents the covariance between features \(i\) and \(j\). Therefore, we have the variance of each feature in the diagonal (\(C_{ii}\) terms).
The eigendecomposition of this matrix into its eigenvalues \(\{\lambda_i\}\) and eigenvectors \(\{\mathbf{v}_i\}\), provides us with the directions along which the data varies the most, i. e., the principal components (PCs). The variance captured by each PC is proportional to its eigenvalue, which allows us to rank them according to the information they provide.
Importantly, PCA offers an interpretable and computationally efficient way to reduce dimensionality, but it is limited to linear transformations. Nonetheless, is a very useful technique for many datasets, as we will see next, and typically serves as a good embedding for more complex tasks. Other nonlinear dimensionality reduction techniques include t-SNE, UMAP, and autoencoders, which we will explore next.
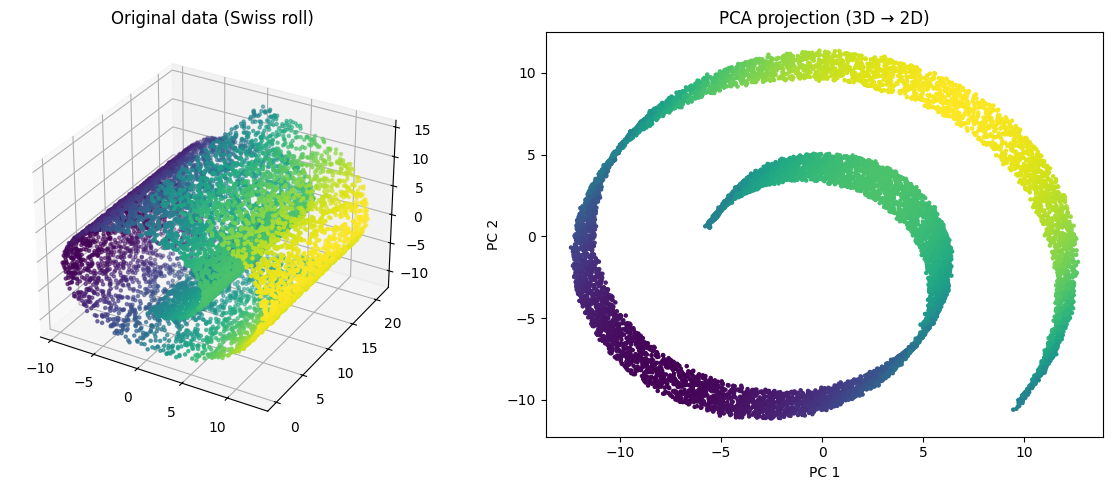
Let’s illustrate PCA with a simple example using sklearn. We will generate a nonlinear 3D dataset (the Swiss roll) and apply PCA to reduce its dimensionality from 3D to 2D.
import numpy as npfrom sklearn.decomposition import PCAfrom sklearn.datasets import make_swiss_roll# Generate a nonlinear 3D dataset (Swiss roll)X, _ = make_swiss_roll(n_samples=10000, noise=0.05)# Apply PCA to reduce 3D → 2Dpca = PCA(n_components=2)X_pca = pca.fit_transform(X)# Plot original data (3D)fig = plt.figure(figsize=(12, 5))ax = fig.add_subplot(1, 2, 1, projection='3d')ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=X[:, 0], cmap='viridis', s=5)ax.set_title("Original data (Swiss roll)")# Plot PCA projectionplt.subplot(1, 2, 2)plt.scatter(X_pca[:, 0], X_pca[:, 1], c=X[:, 0], cmap='viridis', s=5)plt.title("PCA projection (3D → 2D)")plt.xlabel("PC 1")plt.ylabel("PC 2")plt.tight_layout()plt.show()
While PCA may seem like a very simple technique, it is already quite useful for simple datasets, as for instance the Ising configurations we use in HW 1:
Linear methods like PCA provide a simple way to reduce dimensionality, but they can only capture structure that lies close to a flat, linear subspace. Many real datasets—such as images, trajectories, or physical configurations—lie on highly curved or multimodal manifolds that PCA cannot represent without distorting their geometry. This makes PCA insufficient whenever the underlying relationships in the data are nonlinear.
Autoencoders address this limitation by learning a nonlinear mapping from the data to a lower-dimensional latent space and back (see original proposal by Hinton et al.). An autoencoder consists of two neural networks: an encoder that projects the input into the latent space, and a decoder that reconstructs the original data from this. The network is trained to minimize the reconstruction error, with the key addition that the dimension of the latent space is usually much lower that the dimension of the data. That encourages the latent representation to capture the most salient features of the data.
Figure 1: Schematic representation of an autoencoder.
In particular, given a data \(D = \{x_1, \dots, x_N\}\) with \(x_i \in \mathbb{R}^d\), the AE is trained via the reconstruction error, typically defined by means of the MSE:
\[\begin{equation}
\mathcal{L} = \frac{1}{N} \sum_{i=1}^N \left\| x_i - \hat{x}_i \right\|^2 ,
\end{equation}\] where \(\hat{x}_i = \text{decoder}(\text{encoder}(x_i))\) is the reconstructed input.
Let’s implement a simple autoencoder using PyTorch and apply it to the Ising configurations. Of course, we can choose the encoder and decoder to be whatever we want! Here, we will use a convolutional architecture, as we know they work well for this dataset.
In this example I will use a different way of training through a highlevel library: FastAI. This library allows you to bundle your training loops, and use different features that will ease your ML trainings. Another great option for this is PyTorch Lightning, which you can also explore.
# First you need to install fastai via pip: pip install fastai# For this example we will need three importsfrom fastai.vision.allimport Learner, Adam, DataLoaders# We then put together both train and validations dataloadersdata = DataLoaders(train_loader, val_loader)# Then we create a Learner object, which bundles together the data, model, loss function and optimizerlearner = Learner(data, Conv_AE(latent_dim=2), loss_func=nn.MSELoss(), opt_func=Adam)# Finally we train the model usinglearner.fit(50, lr =1e-3)
fastai will save in the learner the model, as well as some training statistics. We can access them as follows:
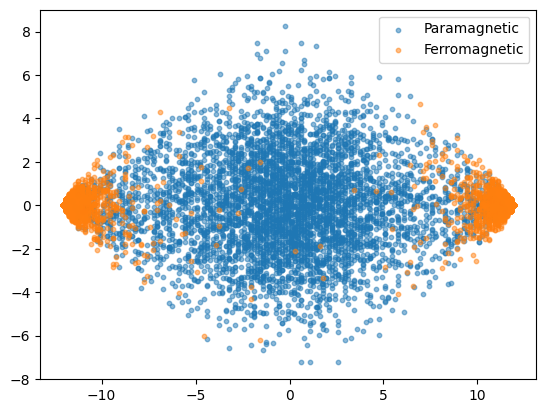
Now let’s look into the latent space of the trained AE. We can access that as follows:
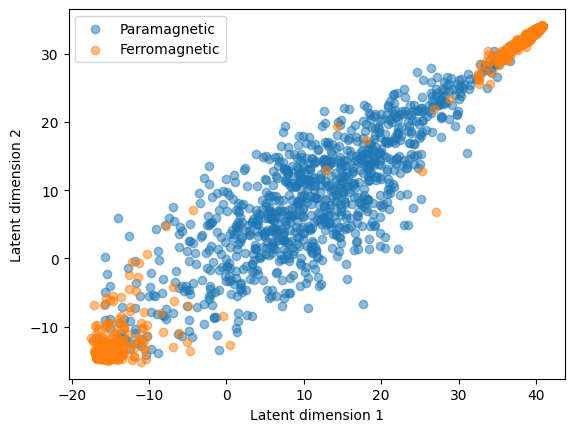
latent = learner.model.encode(X_e)# Let's put everything in the CPU (if you trained in GPU) to ease plottinglatent = latent.cpu().detach().numpy()# And plotplt.scatter(latent[Y_e ==0, 0], latent[Y_e ==0, 1], alpha =0.5, label='Paramagnetic')plt.scatter(latent[Y_e ==1, 0], latent[Y_e ==1, 1], alpha =0.5, label='Ferromagnetic')plt.xlabel('Latent dimension 1')plt.ylabel('Latent dimension 2')plt.legend()
<matplotlib.legend.Legend at 0x7c7001fd5cd0>
As you can see, the AE has learned a representation that again separates both phases quite well, kind of on the same level as the PCA. Now that we have this nice learned distribution, we can for instance use a k-means clustering and see if we would be able to actually classify these two phases. We will consider here a LOT of assumptions and prior knowledge, as for instance that there are 2 phases, and that that the ferromagnetic has two opposite blobs. Nonetheless, we could inspect the configurations and see that one blob contains configurations with positive magnetization, and the other with negative magnetization.
# We now consider here 3 clusters (because of the two blobs of ferromagnetic)kmeans = KMeans(n_clusters =3, random_state=0)kmeans.fit(latent)# Predicted cluster labelsy_pred = kmeans.labels_# Cluster centerscenters = kmeans.cluster_centers_# Plotplt.scatter(latent[:, 0], latent[:, 1], c=y_pred, s=30, cmap='cividis', alpha =0.5)plt.title("k-means clustering with sklearn")
Text(0.5, 1.0, 'k-means clustering with sklearn')
As we can see, k-means does an okay job. Let’s quantify it with the accuracy score:
# We change the labels to match the true labels and be able to compute accuracy# This adaption may need to be changed depending on the results of k-means!y_pred_adjusted = y_pred.copy()y_pred_adjusted[(y_pred_adjusted ==0) | (y_pred_adjusted ==1)] =3y_pred_adjusted -=2# And now we compute the accuracynp.mean(y_pred_adjusted == Y_e.numpy())
np.float64(0.882)
As you can see, we end up having a very decent accuracy, not that bad at all for a “completely” unsupervised approach!
Exercise - Denoising with AE
AE can also be used for many different purposes. A common one is denoising. The idea is to train the AE to reconstruct clean images from noisy ones. This can be done by adding noise to the input images during training, and using the original clean images as targets. The AE learns to remove the noise and recover the underlying structure of the data. Another common application is colouring, where the input image is black and white and the output is the colored one.
For this task, let’s consider a simple purely convolutional AE:
Use this to create the data and then train the AE to denoise images. At the end of the training, visualize the denoised images for the validation dataset, comparing them to the original, clean ones.